电子书 Flink原理与实战(java版)专栏文章入口:电子书 Flink原理与实战(java版)- 目录结构
本章分为如下几篇:
Flink原理与实战(java版)#第3章 Flink的工作原理与架构(整章)
Flink原理与实战(java版)#第3章 Flink的工作原理与架构(第一节流处理和第二节有状态流处理)
Flink原理与实战(java版)#第3章 Flink的工作原理与架构(第三节及时流处理和第四节Flink架构)
Flink原理与实战(java版)#第3章 Flink的工作原理与架构(第五节作业调度和第六节任务生命周期)
Flink原理与实战(java版)#第3章 Flink的工作原理与架构(第七节容错和第八节本章小结)
在自然环境中,数据的产生本质上是流式的。无论是来自 Web 服务器的事件数据、证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,这些数据都是以流的形式产生的。然而,在分析数据时,我们可以采用有界流(bounded)或无界流(unbounded)两种模型来组织和处理数据。当然,根据选择的模型不同,程序的执行和处理方式也会有所不同。如图3-1所示。
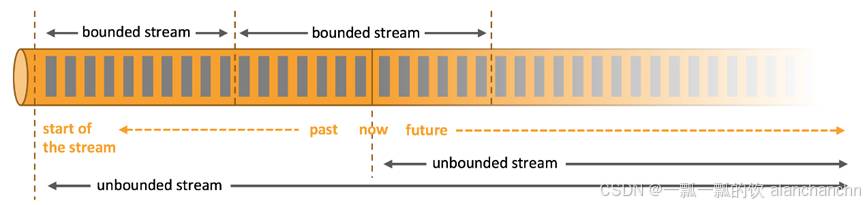
图3-1
该部分内容在本书第二章的“Flink编程模型”中进行了介绍。
在处理流式数据时,我们通常更关注事件本身发生的顺序,而非传输或处理的顺序。这有助于推断出一组事件何时发生以及结束,例如电子商务或金融交易中的事件集合。为了满足实时流处理的需求,我们通常会使用记录在数据流中的事件时间的时间戳,而不是依赖于处理数据的机器时钟的时间戳。
这

