使用vllm能够部署一个非常方便使用的大模型的后端,供webui前端使用,它不仅能够加速模型的推理过程,包括支持fast-attn库,而且还具有很友好的openai风格的api调用功能。
vllm还是有一定的安装需求,根据官方文档,使用如下进行安装。
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.9 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllm
这里没有提及fast-attn的使用,如果没有安装默认使用的是XFormers的backend,建议有条件的话可以通过以下命令再安装一下fast-attn。
pip install flash-attn
首先我们需要下载需要的模型,如果不下载的话,默认的模型会从huggingface的模型库中下载。这里我们本地模型的地址是/data/nlp/models/llama3_7b_instruct。那么只需要执行以下代码。
CUDA_VISIBLE_DEVICES=0 nohup python -m vllm.entrypoints.openai.api_server --model /data/nlp/models/llama3_8b_instruct --served-model-name llama3_8b_instruct --dtype=half > vllm_test.out &
这里served-model-name指的是模型加载到api接口后的模型名(当然你可以将其改为gpt-3.5 turbo,让llama3来代替gpt-3.5节省成本),后面dtype=half是半精度加载。不过vllm已经充分考虑了显存大小进行一个合适的加载了。以llama3_8b_instruct为例,长度默认是4096,加载后显存占用22G,它会预先占用好显存。这里默认的端口是8000,也可以通过--port更改访问端口。
当命令行显式出INFO 04-26 13:08:05 selector.py:28] Using FlashAttention backend.或者INFO 04-26 10:05:08 selector.py:33] Using XFormers backend.的时候,就证明启动成功了。
关于vllm的参数详细介绍,可以参考其参数解读。
调用模型可以通过curl或者python代码调用,风格是和openai的api一样的。
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3_8b_instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'
或者
```python
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="llama3_8b_instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
更多的使用,可以参见它的官方文档或者github用于二次改造,比如它的templete的自定义等。
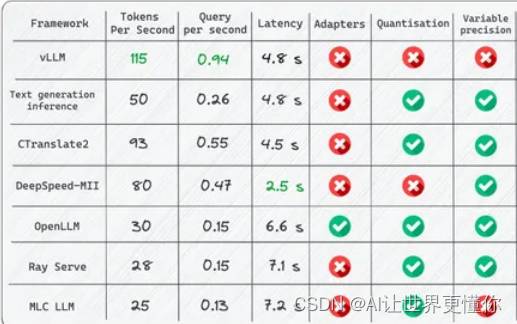
当然,也有很多其他的推理框架,比如,OpenLLM,DeepSpeed等,可以看一下推理框架对比。
版权说明:如非注明,本站文章均为 扬州驻场服务-网络设备调试-监控维修-南京泽同信息科技有限公司 原创,转载请注明出处和附带本文链接。
请在这里放置你的在线分享代码