
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
记得2018年我在一家电商平台负责用户行为分析项目时,团队仅凭经验直觉做决策,结果导致新功能上线后用户留存率下降了15%。这次惨痛的教训让我深刻认识到,没有数据支撑的业务决策就像是在黑暗中射箭,命中率全靠运气。
实证分析(Empirical Analysis)作为一种基于真实数据验证假设的方法论,正在重塑现代企业的决策模式。它不仅仅是统计学的应用,更是一种科学的思维方式,通过严谨的数据收集、处理、分析和解释过程,帮助我们从复杂的现象中发现规律,从噪声中提取信号,从相关性中推断因果性。
在这篇文章中,我将结合自己多年来在金融、电商、互联网等多个行业的实战经验,系统地介绍实证分析的核心方法论、技术工具栈、实施流程以及常见陷阱。从基础的描述性统计到复杂的因果推断,从传统的统计检验到现代的机器学习方法,我将用通俗易懂的语言和丰富的案例,带你深入理解实证分析的技术精髓。
无论你是数据分析师、产品经理,还是希望用数据说话的技术管理者,相信这篇文章都能为你提供实用的技术指导和深刻的思维启发。让我们一起探索数据背后的真相,用实证分析为业务决策装上科学的翅膀!
实证分析是一种基于观察数据和实验数据来验证理论假设的科学研究方法。与纯理论推导不同,实证分析强调"让数据说话",通过系统的数据收集和统计分析来检验理论模型的有效性。
在数据科学领域,实证分析通常包括以下几个核心环节:
理解实证分析与规范分析的区别对于正确应用分析方法至关重要:
| 分析类型 | 核心特征 | 研究问题 | 数据角色 | 典型应用 |
|---|---|---|---|---|
| 实证分析 | 描述"是什么" | 现象之间的真实关系 | 验证理论假设 | 用户行为分析、市场响应研究 |
| 规范分析 | 描述"应该是什么" | 理想状态或最优解 | 支撑价值判断 | 政策评估、策略优化建议 |
现代实证分析离不开强大的技术工具支撑,主要技术栈包括:
数据处理工具:
统计分析工具:
可视化工具:
机器学习工具:
“相关不等于因果” —— 这是每个数据分析师必须牢记的金科玉律
在实证分析中,建立因果关系是最具挑战性的任务。Rubin因果模型(RCM)提供了严谨的因果推断框架:
核心概念:
识别策略:
良好的实验设计是获得可信实证结果的基础,需要遵循以下原则:
随机化原则:
对照原则:
重复原则:
选择合适的统计检验方法对于得出正确结论至关重要:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
def comprehensive_statistical_test(data_before, data_after, alpha=0.05):
"""
综合统计检验函数
包含正态性检验、方差齐性检验和均值比较
"""
# 正态性检验
_, p_normal_before = stats.normaltest(data_before)
_, p_normal_after = stats.normaltest(data_after)
print(f"正态性检验 p值: 处理前={p_normal_before:.4f}, 处理后={p_normal_after:.4f}")
# 根据正态性选择检验方法
if p_normal_before > alpha and p_normal_after > alpha:
# 两个样本都服从正态分布,使用t检验
_, p_value = stats.ttest_rel(data_before, data_after)
test_method = "配对t检验"
else:
# 至少一个样本不服从正态分布,使用非参数检验
_, p_value = stats.wilcoxon(data_before, data_after)
test_method = "Wilcoxon符号秩检验"
# 效应量计算(Cohen's d)
diff = np.array(data_after) - np.array(data_before)
cohens_d = np.mean(diff) / np.std(diff, ddof=1)
# 置信区间
ci_low, ci_high = stats.t.interval(1-alpha, len(diff)-1,
loc=np.mean(diff),
scale=stats.sem(diff))
return {
'test_method': test_method,
'p_value': p_value,
'cohens_d': cohens_d,
'ci_95': (ci_low, ci_high),
'significant': p_value < alpha
}
# 示例数据:A/B测试中的转化率对比
control_group = np.array([0.12, 0.15, 0.18, 0.14, 0.16, 0.13, 0.17, 0.19, 0.11, 0.20])
treatment_group = np.array([0.22, 0.25, 0.28, 0.24, 0.26, 0.23, 0.27, 0.29, 0.21, 0.30])
result = comprehensive_statistical_test(control_group, treatment_group)
print(f"检验方法: {result['test_method']}")
print(f"p值: {result['p_value']:.4f}")
print(f"Cohen's d: {result['cohens_d']:.4f}")
print(f"95%置信区间: [{result['ci_95'][0]:.4f}, {result['ci_95'][1]:.4f}]")
print(f"统计显著: {result['significant']}")
关键点评:
A/B测试是互联网产品优化中最常用的实证分析方法。下面是一个完整的A/B测试分析流程:
图1:A/B测试完整流程时序图 - sequenceDiagram类型,展示了从用户访问到最终分析的完整实验流程
用户行为路径分析帮助我们理解用户在产品中的真实使用模式:
import pandas as pd
import numpy as np
from collections import defaultdict
class UserPathAnalyzer:
"""用户行为路径分析器"""
def __init__(self):
self.paths = defaultdict(list)
self.conversions = defaultdict(int)
def add_user_journey(self, user_id, events):
"""添加用户行为序列"""
# 提取事件类型序列
event_sequence = [event['event_type'] for event in sorted(events, key=lambda x: x['timestamp'])]
self.paths[user_id] = event_sequence
# 检查是否转化
if any(event['event_type'] == 'purchase' for event in events):
self.conversions[user_id] = 1
def analyze_common_paths(self, min_length=3):
"""分析最常见的用户路径"""
path_counts = defaultdict(int)
path_conversions = defaultdict(int)
for user_id, path in self.paths.items():
if len(path) >= min_length:
# 生成子路径
for i in range(len(path) - min_length + 1):
subpath = tuple(path[i:i+min_length])
path_counts[subpath] += 1
path_conversions[subpath] += self.conversions[user_id]
# 计算转化率
path_analysis = []
for path, count in path_counts.items():
conversion_rate = path_conversions[path] / count if count > 0 else 0
path_analysis.append({
'path': ' -> '.join(path),
'frequency': count,
'conversions': path_conversions[path],
'conversion_rate': conversion_rate
})
return sorted(path_analysis, key=lambda x: x['conversion_rate'], reverse=True)
# 示例数据
sample_data = [
{'user_id': 1, 'event_type': 'view_homepage', 'timestamp': '2024-01-01 10:00:00'},
{'user_id': 1, 'event_type': 'view_product', 'timestamp': '2024-01-01 10:01:00'},
{'user_id': 1, 'event_type': 'add_to_cart', 'timestamp': '2024-01-01 10:02:00'},
{'user_id': 1, 'event_type': 'purchase', 'timestamp': '2024-01-01 10:03:00'},
{'user_id': 2, 'event_type': 'view_homepage', 'timestamp': '2024-01-01 10:05:00'},
{'user_id': 2, 'event_type': 'view_product', 'timestamp': '2024-01-01 10:06:00'},
{'user_id': 2, 'event_type': 'exit', 'timestamp': '2024-01-01 10:07:00'},
]
# 分析用户路径
analyzer = UserPathAnalyzer()
for user_id in set(event['user_id'] for event in sample_data):
user_events = [event for event in sample_data if event['user_id'] == user_id]
analyzer.add_user_journey(user_id, user_events)
results = analyzer.analyze_common_paths(min_length=2)
for result in results:
print(f"路径: {result['path']}")
print(f"频次: {result['frequency']}, 转化率: {result['conversion_rate']:.2%}")
print("-" * 50)
关键点评:
多渠道归因分析帮助我们理解不同营销渠道对最终转化的贡献:
图2:营销渠道转化贡献饼图 - pie类型,展示了不同营销渠道对最终转化的贡献比例
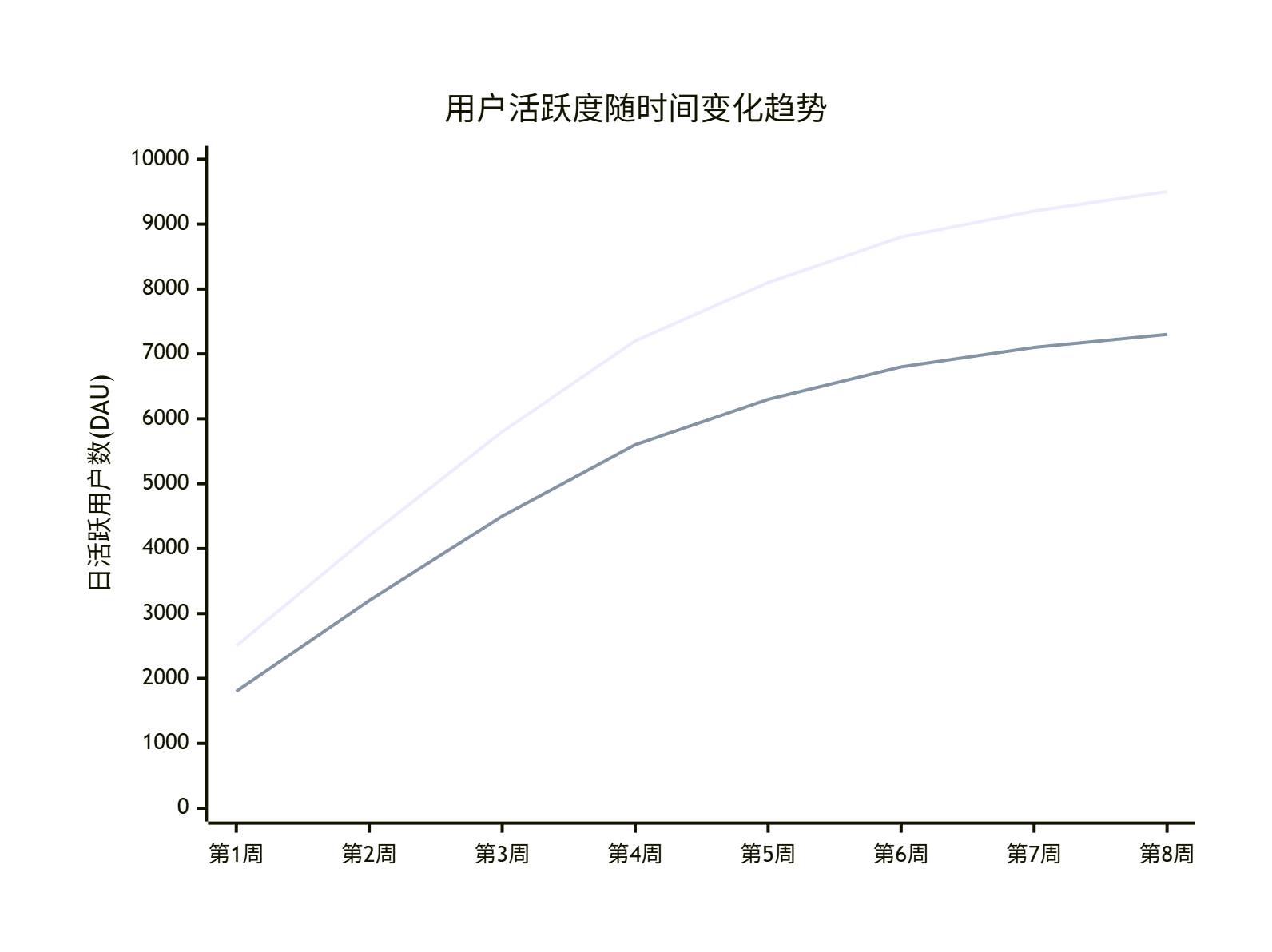
图3:用户活跃度趋势图 - xychart-beta类型,展示了新老用户的活跃度变化趋势
选择性偏差是实证分析中最常见也最容易被忽视的问题:
表现形式:
检测方法:
def detect_selection_bias(df, treatment_col, outcome_col, covariates):
"""
检测选择性偏差的简单方法
"""
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
# 构建处理状态预测模型
X = df[covariates]
y = df[treatment_col]
model = LogisticRegression()
model.fit(X, y)
# 预测处理概率(倾向得分)
propensity_scores = model.predict_proba(X)[:, 1]
# 检查倾向得分的重叠性
treated_ps = propensity_scores[y == 1]
control_ps = propensity_scores[y == 0]
# 计算重叠区域
overlap_region = (max(min(treated_ps), min(control_ps)),
min(max(treated_ps), max(control_ps)))
# AUC作为预测能力的指标
auc = roc_auc_score(y, propensity_scores)
return {
'overlap_region': overlap_region,
'auc': auc,
'has_selection_bias': auc > 0.8, # AUC过高表明处理分配可预测性强
'propensity_scores': propensity_scores
}
混淆变量同时影响处理变量和结果变量,会导致虚假的因果推断:
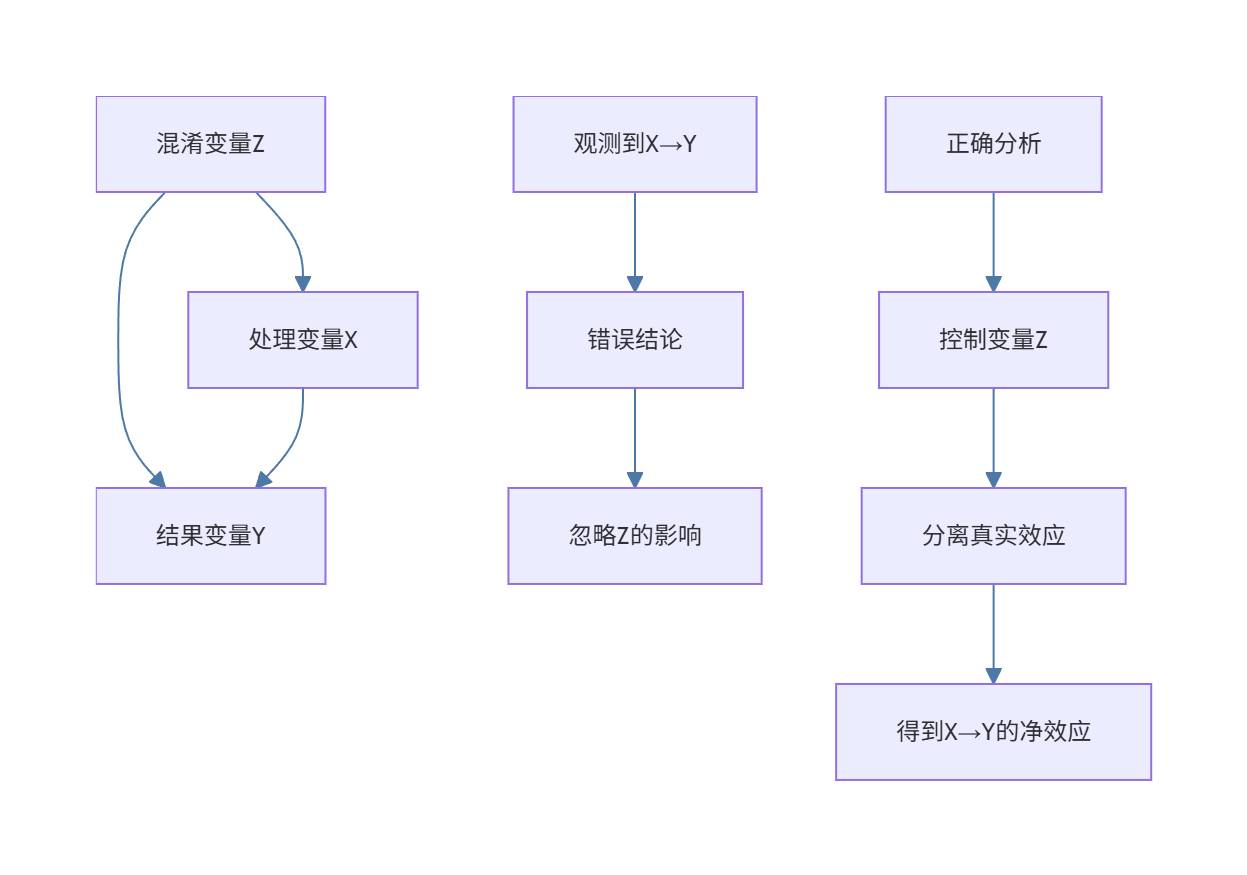
图4:混淆变量影响分析流程图 - flowchart类型,展示了混淆变量如何影响因果推断以及如何正确处理
当进行多个统计检验时,假阳性率会显著增加:
问题描述:
解决方案:
def multiple_testing_correction(p_values, method='fdr_bh'):
"""
多重检验校正
"""
from statsmodels.stats.multitest import multipletests
# 应用校正方法
rejected, corrected_p_values, _, _ = multipletests(
p_values, alpha=0.05, method=method
)
return {
'rejected': rejected,
'corrected_p_values': corrected_p_values,
'original_significant': sum(p < 0.05 for p in p_values),
'corrected_significant': sum(rejected)
}
# 示例:20个p值的多重检验校正
np.random.seed(42)
p_values = np.random.uniform(0, 1, 20) # 模拟20个p值
result = multiple_testing_correction(p_values)
print(f"原始显著结果数量: {result['original_significant']}")
print(f"校正后显著结果数量: {result['corrected_significant']}")
print(f"校正方法: Benjamini-Hochberg FDR控制")
建立标准化的分析流程可以提高分析质量和效率:
问题定义阶段:
数据准备阶段:
分析建模阶段:
结果解释阶段:
报告输出阶段:
确保分析结果可重现是科学研究的基本要求:
# 设置随机种子确保结果可重现
np.random.seed(42)
random.seed(42)
# 版本控制关键依赖
import sklearn
import pandas as pd
import numpy as np
print(f"scikit-learn版本: {sklearn.__version__}")
print(f"pandas版本: {pd.__version__}")
print(f"numpy版本: {np.__version__}")
# 保存分析配置
analysis_config = {
'sample_size': 1000,
'significance_level': 0.05,
'test_method': 'mann-whitney',
'bootstrap_iterations': 1000,
'random_seed': 42
}
# 将配置保存为JSON文件便于追踪
import json
with open('analysis_config.json', 'w') as f:
json.dump(analysis_config, f, indent=2)
实证分析的最终目标是为业务决策提供支撑,因此必须能量化分析的业务价值:
ROI计算公式:
分析ROI = (业务改进收益 - 分析成本) / 分析成本 × 100%
业务价值评估框架:
回顾我多年来在实证分析领域的探索历程,我深刻体会到:数据本身并不会说话,是我们通过科学的方法让数据开口。实证分析不仅仅是一套技术工具,更是一种思维方式,它教会我们在面对复杂问题时如何保持理性、严谨和谦逊。
在这篇文章中,我从实证分析的基本概念出发,系统地介绍了因果推断框架、统计检验方法、实战应用案例以及常见陷阱。每一个概念背后都有着我亲身经历的失败教训和成功经验。记得在一次营销效果评估项目中,由于没有充分考虑季节性因素,我们差点做出了错误的渠道投资决策。正是这些经历让我明白,实证分析中的每一个步骤都至关重要,任何一个环节的疏忽都可能导致结论的偏差。
技术在不断进步,新的算法和工具层出不穷,但实证分析的核心原则始终不变:明确的问题定义、严谨的研究设计、恰当的分析方法、审慎的结果解释。我始终相信,真正有价值的分析不是最复杂的分析,而是最能回答业务问题的分析。在追求技术精进的同时,我们更要保持对业务本质的理解和对实际问题的关注。
展望未来,随着大数据和人工智能技术的发展,实证分析将面临新的机遇和挑战。更丰富的数据来源、更强大的计算能力、更先进的算法模型,这些都为我们提供了前所未有的分析能力。但同时,我们也面临着数据质量、算法偏见、隐私保护等新的挑战。
我想对所有正在数据科学道路上探索的朋友们说:保持好奇心,保持批判性思维,永远不要让工具驾驭了问题。记住,我们不是在寻找数据来证明自己是对的,而是在寻找数据来发现真相。让实证分析成为你决策路上的明灯,但永远不要忘记,最终的决定权在于你对业务的深刻理解和对用户的真诚关怀。
数据科学之路永无止境,愿我们都能在数据的海洋中找到属于自己的北极星,用科学的方法照亮前行的道路,用实证的精神追求真理的光芒!
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!

